
Hyunebee
메모리 관리 - 페이징, 세그먼테이션 본문
메모리 관리
프로세스들을 위해 메모리를 할당하고 회수하고 보호하는 활동
여러 프로세스가 메모리 위에 올라갈 수 있게 운영체제가 메모리를 동적으로 세분화해줌
메모리 관리 정책
1. 적재 정책 - 디스크에서 메모리로 언제 들여올지 (When)
-요구 적재 : 요청시 적재
-예상 적재 : 예측되는 참조 요청까지 미리 적재
2. 배치 정책 - 메모리의 어느 위치에 저장할지(Where)
3. 교체 정책 - 메모리가 충분하지 않을때 현재 메모리에서 제거할 부분을 결정(How)
메모리의 구조
1.논리적 관점 : 프로그래밍에 사용하는 공간 -> 덧셈하는 공간 / 배열공간 등등
2.물리적 관점 : 실제 데이터나 프로그램을 저장하는 공간 // 배열 공간의 인덱스 처음부터 끝까지 등등
이 두개의 논리적 메모리와 물리적 메모리가 매핑되어야한다. -> 이 작업을 주소 바인딩이라고 한다.
주소 바인딩의 방식(https://jhnyang.tistory.com/247?category=815411)
프로그램이 적재되는 물리적 메모리의 주소가 결정되는 시기에 따라 세 가지로 분류할 수 있습니다.
(1) 컴파일 타임 바인딩(Compile time binding)
물리적 메모리 주소가 프로그램을 컴파일 할 때 결정되는 주소 바인딩 방식
즉, 프로그램 내부에서 사용하는 주소와 물리적 메모리 주소가 동일.
-> 물리적 메모리 위치를 변경하려면 컴파일을 다시 해야 하며, 잘 사용하지 않는 기법
-> 만약 이미 다른 프로세스가 메모리를 차지하고 있는 경우도 존재할 수 있습니다.
-> 즉 하나의 프로세스만을 사용하는 것이 확실 할 때만 사용합니다.
(2) 로드 타임 바인딩(Load time binding)
프로그램의 실행이 시작될 때 물리적 메모리의 주소가 결정되는 주소 바인딩 방식
로더(loader)의 책임하에 물리적 메모리 주소가 부여되며, 프로그램이 종료될 때까지 물리적 메모리 상의 위치가 고정 됩니다. (로더란 사용자 프로그램을 메모리에 적재시키는 프로그램)
결과적으로 프로그램 내부에서 사용하는 주소와 물리적 메모리 주소는 다른 방식입니다.
물리적 메모리 주소와 논리적 메모리 주소를 분리하여 컴파일 타임 바인딩과는 다르게 multiprogramming이 가능합 니다.
문제는 메모리를 참조하는 명령어를 다 변경해줘야 한다는 점으로 메모리 로딩 시간이 엄청 오래 걸리는 단점이 있습 니다. 그래서 실제로 사용하는 방식은 아닙니다.
(3) 실행시간 바인딩(execution time binding or run time binding)
프로그램이 실행을 시작한 이후에도 프로그램이 위치한 물리적 메모리상의 주소가 변경될 수 있는 바인딩 방식
이 방식은 cpu가 주소를 참조할 때마다 해당 데이터의 물리적 메모리가 어디에 위치해야 하는지, 주소 매핑 테이블 (address mapping table)을 이용해 바인딩을 점검합니다. 또한, 다른 방식들과 다르게 실행시간에 바인딩이 이루어지 므로 기준 레지스터와 한계 레지스터를 포함한 MMU라는 하드웨어적인 지원이 뒷받침 되어야 합니다. (MMU는 논리 적 주소를 물리적 주소로 매핑해주는 하드웨어 장치)
(4) 로드 타임 바인딩과 실행 시간 바인딩의 차이점
로드 타임은 메모리에 로딩할 때 주소 변환 작업을 미리 다 해놓지만 반면에 실행 시간 바인딩은 실행 할때 하게 됩니 다. 즉, 로드타임은 한 번만 바꿔 놓게 되면 똑같은 해당 주소로 접근하면 됩니다. 그러나 실행 시간 바인딩의 경우 변 환 작업을 수행하고 메모리에 접근하게 됩니다.
위와 같은 차이점만 보게 되면 로드 타임이 더욱 좋아 보이지만, 하드웨어 성능이 높아져서 하드웨어 상의 로직 수행 으로 실행 시간 바인딩을 수행해도 성능 상 문제가 없다고 합니다.
그러나 로드의 경우 메모리 로딩시의 오버헤드가 큰 관계로 사용하지 않습니다.
MMU -> Memory Management Unit
논리주소를 물리 주소로 바꾸는 하드웨어 장치이다.
동적 적재
-동적 링킹이라고도 한다. 프로그램 내의 루틴이 호출되는 시점에 적재
-실행파일에는 처음에 포함하지 않았다가 실행시에 올려서 사용
장점
1.프로그램 초기 적재시간 절약
2.메모리 절약 -> 사용되지 않는 루틴은 메모리에 적재되지 않음
중첩
-실제 메모리보다 큰 프로그램을 실행하는 기술 -> 가상메모리와 같다.
-공통적으로 필요한 부분은 공통 루틴에 포함해서 메모리에 올리고 서로 다른 기능을 수행하는 부분은 중첩영역에 그
기능을 사용할때마다 번갈아 가면서 메모리에 올려서 사용한다.
-프로그래머가 직접 나눠서 중첩을함 -> 가상메모리와의 차이점
연속 vs 불연속 메모리 할당
| 연속 | 불연속 | |
| 개념 | 한 프로세스에 연속된 메모리할당 | 한 프로세스에 불연속적 메모리할당 |
| 프로세스 수행시간 | 짧다 -> 연속해 붙어있음으로 | 길다. -> 떨어져있음으로 |
| 오버헤드 | 적다 -> 주소변환이 단순하다. | 많다. -> 주소변환이 복잡하다. |
| OS제어 | 쉽다. | 어렵다. |
| 내부 단편화 | 고정 분할 : 있다. 가변 분할 : 없다. |
페이징 : 있다. 세그멘테이션 : 없다. |
| 외부 단편화 | 고정 분할 : 없다. 가변 분할 : 있다. |
페이징 : 없다. 세그멘테이션 : 있다. |
큰 그림을 살펴보면 아래와 같다.
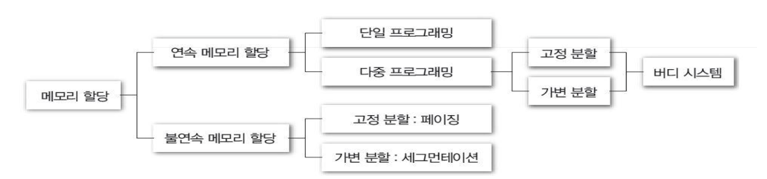
고정분할/가변분할
고정분할 : 메모리를 미리 분할하여 프로세스에게 분할된 영역을 할당(크기는 상관없다.)
미리 분할해 둠으로 OS의 제어가 쉽고 내부 단편화가 있다.
가변분할 : 메모리를 프로세스가 요구하는 영역을 만큼을 할당(크기는 상관없다.)
요구마다 분할크기가 다름으로 OS의 제어가 어렵고 외부 단편화가 있다.
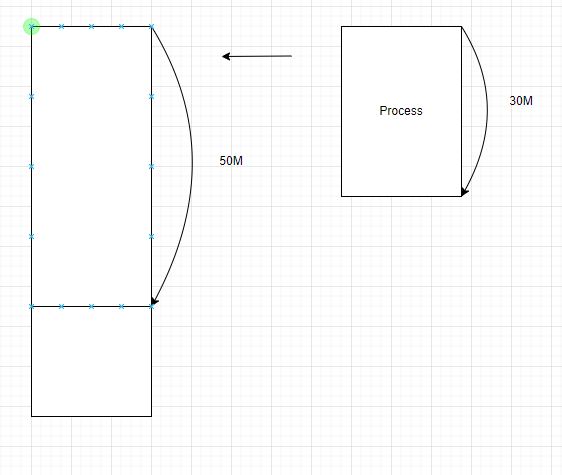
내부 단편화/외부 단편화
내부 단편화
고정 분할시 미리 정해둔 빈 공간의 크기보다 작은 메모리를 할당할 경우 발생하는것이
내부 단편화 이다. 아래 그림과 같이 고정분할을 50M로 하고 30M를 할당해줬을때 20M의
메모리가 낭비

외부 단편화
가변분할의 경우 프로세스가 요구하는 만큼의 메모리를 내어준다. a~d까지는 요청한 메모리 만큼
의 공간을 할당해준다. e부터는 메모리를 반납하고 빈공간에 새로운 프로세스가 들어가고 있다.
만약 h그림에서 7M의 메모리 사용공간을 요구한다면 빈공간은 남아있지만 적재를 하지 못하게 된다.
그래서 남은 메모리를 모아서 작업을 할당해야한다. 이때문에 고정분할보다 오버헤드가 크다.

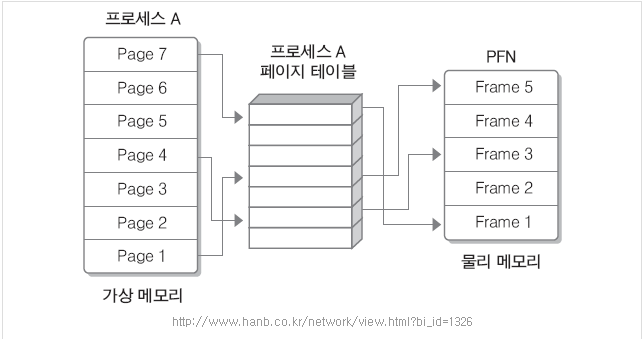
페이징(불연속 메모리 할당)
프로세스의 가상 메모리를 동일한 사이즈의 페이지 단위로 나우어 물리적 메모리에 불연속적으로 저장하는 방식
이때 Page의 크기는 Frame의 크기와 같다.
해석해보면 Page 7번은 Frame1번에 들어있다. 페이지 4번은 Frame 3번에 들어있다.
아래그림은 위의 그림보다 조금 자세하게 페이지 기법을 보여준다.
가상 주소는 앞단은 페이지의 번호 뒷단은 물리적 주소에서 페이지의 위치를 나타내는 offset이다.

페이징의 특징
1.빈 프레임에 어떤 페이지든 적재할 수 있음
2.외부단편화 없음 -> 페이지 단위로 들어오기 때문에 다 활용할수있다.
3.OS가 페이지 관리를 함으로 부담이 크다.
4.내부단편화 발생 -> 페이지 단위로 맞춰야하기때문에 마지막 페이지 번호에 내부 단편화가 생길 수 있음
위의 특징처럼 페이지 테이블의 구현은 메모리 액세스 성능을 좌우한다. 만약 테이블 안에 테이블이있는 다단계
테이블 구조라면 더욱이 큰 영향을 줄것이다.
페이지 테이블 구현 방법
1.직접 매핑 - 메모리 적재
페이지 테이블 기준 주소는 PCB에 저장 -> 페이지 테이블 기준 레지스터
2.연관 매핑 - 연관 기억 장치에 적재
주소로 찾는게 아니라 값(key)으로 찾음
3.연관 직접 결합 매핑 - 페이지 테이블의 일부는 연관 나머지는 메모리
공유 페이지
-공통 코드나 공유 라이브러리 코드에 적용
-읽기는 가능하나 수정은 불가능하다.
-여러 프로세스가 동시에 수행이 가능하다.
세그먼테이션(불연속 메모리할당)
프로세스 주소 공간을 세그먼트로 나누어 불연속적으로 할당 -> 가변 분할 방법으로 할당
아래의 그림을 보면 세그먼테이션 테이블에는 시작점(base)과 크기(limit)을 알려주고있음

위 그림을 보면 페이징과 다른점을 알수있다.
페이지는 같은 크기의 불연속 적재이고 세그먼테이션은 다른 크기의 불연속 적재이다.
세그먼테이션의 특징
1. 외부단편화가 있다.
2. 일반적으로 페이지 테이블보다 세그먼트 테이블이 작다.
3. 연속된 공간에 할당하는것보다. 쉽다 but 메모리 할당시 동일 크기 가용 공간을 찾는 것보다 비효율적이다.
4. 메모리 스왑시 세그먼트의 크기가 다양하기 때문에 비효율적이다.


